[TOC]
1.宏观
锁是计算机协调多个进程或线程并发访问某一资源的机制
1.数据库锁
- 粒度小,方便用于集群环境
2.代码锁
- 粒度大,需要封装
2.微观(操作粒度)
1.分类(种类)
1.行锁 & 表锁
只有明确指定明确指定主键才会执行行锁,否则执行表锁
-
无锁
select * from user where id = -1 for update;id是从1开始自增,这里为-1所以这个主键是不存在的
-
行锁(偏写)
select * from user where id = 3 for update; select * from user where id = 1 and name = 'KKK' for update;这些都会执行行锁
-
表锁(偏读)
#主键不明确 select * from where name = 'kk' for update; select * from where id <> 3 for update;
2.表锁分析
**1.特点:**偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁粒度大,发生锁冲突的概率最高,并发度最低.
-- 加锁
lock table mylock read,book write;
-- 解锁
unlock tables;
-
读锁
session_1 session_2 session1给表mylock加读锁 session2链接终端 session1可以查询该表记录 session2也可以查询该表记录 session1不能查询其它没有加锁的表 session2可以查询或更新未加锁的表 session1插入或更新mylock都会报错,最后释放锁 session2插入或更新mylock会一直等待获取锁,1释放完2获取锁更新 -
写锁:
session_1 session_2 获得表mylock的write锁定 待session1开启写锁,session2连接终端 session1对锁定表mylock更新读取都可以 session2对锁定表查询被阻塞,需要等待锁释放 释放锁 session2获取锁,进行查询
2.总结:读锁会阻塞写,但是不阻塞读,而写锁则是把读和写全阻塞.
-- 看哪些表被锁
show open tables;
-- 如何分析表锁定
show status like 'table%';
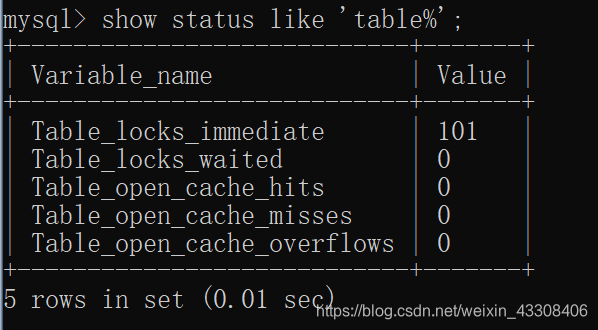
- Table_locks_immediate:产生表级锁定的次数,表示可以立即获取锁的查询次数.,每次获取锁值加1
- Table_locks_waited:出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次锁值加),此值高则说明存在着较严重的表级锁争用情况
MyISAM的读写调度是优先,这也是MyISAM不适合做写为主表的引擎,因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永久阻塞.
4.行锁分析
**1.特点:**偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁粒度小,发生锁冲突的概率最低,并发也是最高.
InnoDB与MyISAM的最大不同有两点:一是事务;二是行级锁;
| session_1 | session_2 |
|---|---|
| set autocommit = 0 | set autocommmit = 0 |
| 更新但不提交,没有手写commit | session_2更新同一条数据,被阻塞 |
| commit; 提交 | 解除阻塞,正常更新 |
| commit; 提交 |
2.索引失效导致行锁升级为表锁,别人无法更新.
3.间隙锁
1.间隙锁带来的插入问题
| session_1 | session_2 |
|---|---|
| 更新表中id>1和id<6,但是id=2已删除,更新成功 | 新增id=2的值,阻塞产生,暂时不能插入 |
| commit; 提交 | 阻塞解除,完成插入 |
2.什么是间隙锁?
当我们用范围查询条件而不是相等条件检索数据,并请求共享或者排他锁,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做"间隙(GAP)";
InnoDB也会对这个"间隙"加锁,这种锁机制就是所谓的间隙锁.
4.如何锁定一行?
begin;
select * from table_names where a = 8 for update;
commit;
锁定一行后,其他操作会被阻塞,直到锁定行的会话提交commit.
InnoDB存储引擎由于实现了行级锁定,虽然在锁定方面所带来的性能损耗可能比表级锁定要更高一些,但是整体并发处理能力方面要远远优于MyISAM的表级锁定的.当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势了.
但是使用不当,会行锁边表锁,让整体性能更弱.
5.分析行锁定
show status like 'XXX%';
参数:
Innodb_row_lock_current_waits: 当前正在等待锁定数量(总等代数);
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度;
Innodb_row_lock_time_avg: 每次等待所花平均时间;
Innodb_row_lock_time_max: 从系统启动到现在等待最常的一次所花时间;
Innodb_row_lock_waits: 系统启动到现在总共等待的次数;
6.行锁优化
1.尽可能让所有数据检索都通过索引来完成,避免五索引行锁升级为表锁.(注意varchar类型,的索引问题)
2.合理设计索引,尽量缩小锁的范围(如范围查询要小心间隙锁)
3.尽可能较少检索条件,避免间隙锁
4.尽量控制事务大小,减少锁定资源和时间长度
5.尽可能低级事务隔离
2.锁算法(机制)
1.行锁算法
-
Record Lock (普通行锁)
- 键值在条件范围内(比如主键id的范围)
- 记录存在
-
Gap Lock (间隙锁)
- 键值不存在条件范围内,叫做"间隙”(GAP),引擎就会对这个"间隙"进行加锁,这种机制就叫做GAP机制
-
Next-Key Lock (行 & 间隙)
- 在键值范围条件内,同时键值又不存在条件范围内.
#id只有1-50 select * from user id > 49 for update;
2.表锁算法
-
意向锁(升级机制)
- 当一个事务带着表锁去访问一个被加了行锁的资源.那么,这个行锁就会升级成为意向锁,将表锁住.
#事务A select * from user where id = 10 for update; #事务B select * from user where name = 'kk' for update;事务A 是加了行锁的,事务B如果区访问name = ‘kk’,他的id为10,那么就满足了意向锁的条件
-
自增锁
- 事务插入自增类型的列时,获取自增锁
如果一个事务正往表中插入自增记录,其他事务必须等待.
3.实现
1.共享锁 & 排它锁
行锁和表锁其实是粒度的概念,共享锁和排它锁是具体的实现
-
共享锁(s)
- 允许一个事务去读一行,阻止其他事务去获取该行的排它锁
-
排它锁(x):写锁
- 允许持有排它锁的事务读写数据,阻止其他事务获取该资源的共享锁和排它锁
- 不能获取任何锁,不代表不能读
-
注意
-
某个事务获取数据的排它锁,其他书屋不能获取该数据的任何锁,并不能代表其他事务不能无锁读取该数据
- 无锁
#不加任何修饰就是无锁 select ... from ....- 共享锁
select .... lock in share modeMySQL 8.0以上,for share 代替了lock in share mode,仍然支持lock in share mode ;但是,nowait,skip lock,配合自旋锁,可以高效的实现一个等待队列.
- 排它锁
update... delete... insert... select...for update
-
2.乐观锁 & 悲观锁
不管是什么锁都需要失败重试
-
乐观锁:一般通过版本号进行更新操作
update user set name = 'ww' where id = 1 and version = 1; -
悲观锁:共享锁和排它锁其实是悲观锁的一个实现